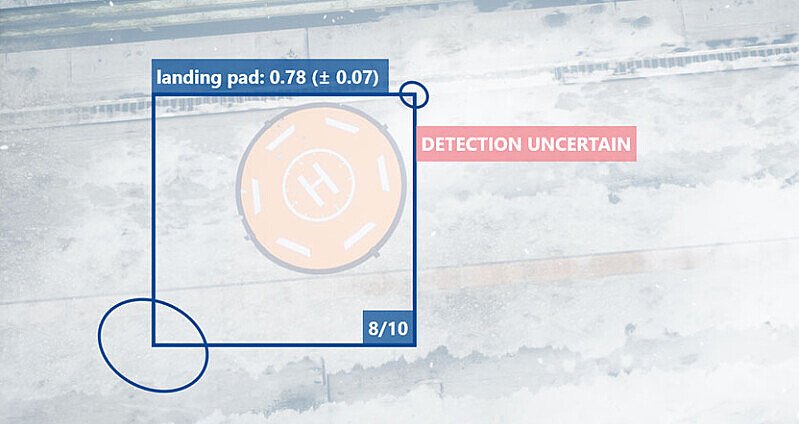
Introduction
In recent years, machine learning (ML) models have become immensely powerful and are used in a wide range of applications and domains. The rise of large language models (LLMs) has led to the popularization of artificial intelligence (AI) in society and boosted the already high interest of the industry. Deep learning models are deployed to estimate depth in 2D images, to predict the number of incidents and needed police deployments, or to convert speech to text, often with impressive results. But regardless of the AI task at hand, the number of parameters, or the used architecture, none of the AI models are perfect. Incorrect predictions and mistakes in outputs generated by the AI are inevitable. The real world is complex, chaotic, dynamically changing, and thus difficult to represent in a training set, from which models gain knowledge. Uncertainty is, therefore, inherent in the model's operation. For humans it is very natural to express uncertainty when faced with a new situation or a difficult question. We use phrases like "maybe", "probably" or "I don't know". Analogously, the goal of uncertainty quantification (UQ) in ML is to enable the models to signal whether they are confident about the provided output or, on the contrary, that they "don't know" and are in fact guessing.
In this article, we dive a little bit deeper into the world of UQ in ML and discuss types of uncertainty, methods and approaches that can be used to estimate uncertainties as well as application areas of ML in which uncertainty quantification is helpful. We also describe selected challenges and our latest standardization activities.
Types of Uncertainty
Beyond its general, non-technical meaning, uncertainty can be analyzed in a more formal way. A common approach to categorize the uncertainties in ML is to distinguish between epistemic and aleatoric uncertainty. Epistemic uncertainty refers to the lack of knowledge in the model and can stem from insufficient amount of data used in a training or suboptimal architecture choices. Epistemic uncertainty is said to be reducible as it can be explained away by increasing the amount of training data. Aleatoric uncertainty, on the other hand, is related to inherent randomness which can be caused e.g., by measurement noise or stochasticity in the data generation process. Rolling dice is an example of such a process (in fact the word "aleator" means "dice player" in Latin). Aleatoric uncertainty is considered irreducible as gathering and using additional samples is not going to reduce it. While the border between the types and simple distinction between reducible and irreducible is often ambiguous, it is important to be aware of this categorization. Knowing which type of uncertainty should be estimated and which type is quantified by the selected UQ approach can contribute, or even be critical, to the success of the developed system.